
A Tarefa
A primeira tarefa é realizar a análise completa de um conjunto de dados oferecido por Akash Patel, no site kaggle.com. Em um segundo momento, com a análise e os processamentos necessários realizados, será realizada a segmentação dos clientes baseados em sua renda, quantas crianças têm, quanto gasta em cada categoria de produtos, quantas compras realiza por cada canal e a interação com as campanhas de marketing da empresa. Depois, vamos utilizar o modelo XGBoost para prever em qual segmento de gastos um cliente que acaba de se cadastrar se encaixaria com maior probabilidade.
EDA — Exploratory Data Analyses
Primeiros Passos
O conjunto de dados fornecido apresenta boa estrutura e coesão, contendo campos que identificam cada cliente (ID), características socioeconômicas (Year_Birth, Education, Marital_Status, Income, Kidhome, Teenhome) e também características do relacionamento dele com a empresa (Dt_Customer — data de inscrição na empresa, Recency — tempo sem realizar compra, NumWebVisitsMonth — número de visitas ao site), além de variáveis que determinam quanto o cliente gasta em cada categoria, quantidade de compras por canal de vendas e atividade de resposta à campanhas de marketing.
Após análise superficial, foram encontrados apenas 24 valores nulos, todos na coluna Income, sendo então substituídos pela renda média dos clientes.
O conjunto de dados fornecido apresenta boa estrutura e coesão, contendo campos que identificam cada cliente (ID), características socioeconômicas (Year_Birth, Education, Marital_Status, Income, Kidhome, Teenhome) e também características do relacionamento dele com a empresa (Dt_Customer — data de inscrição na empresa, Recency — tempo sem realizar compra, NumWebVisitsMonth — número de visitas ao site), além de variáveis que determinam quanto o cliente gasta em cada categoria, quantidade de compras por canal de vendas e atividade de resposta à campanhas de marketing.
Após análise superficial, foram encontrados apenas 24 valores nulos, todos na coluna Income, sendo então substituídos pela renda média dos clientes.
Foram retiradas também, as variáveis que não eram informativas, no caso Z_Revenue e Z_CostContact, já que todas tinham o mesmo valor para todos os registros, visando assim diminuir a utilização de memória e processamento desnecessários.
Automatic EDA — Análise Exploratória Automática
Para facilitar o entendimento do banco de dados que possui 2240 registros e 29 variáveis, utilizamos a técnica de EDA automático, através da biblioteca SweetViz.
Parte 1 | Análise aprofundada das features
Baseados na análise automática, podemos partir para uma análise mais aprofundada das variáveis.
Variável Income (renda) — Qual o impacto do nível de educação na renda?
A variável Income mostra uma grande distinção entre os clientes de educação básica e os demais que, por sua vez, não são tão diferentes entre si.
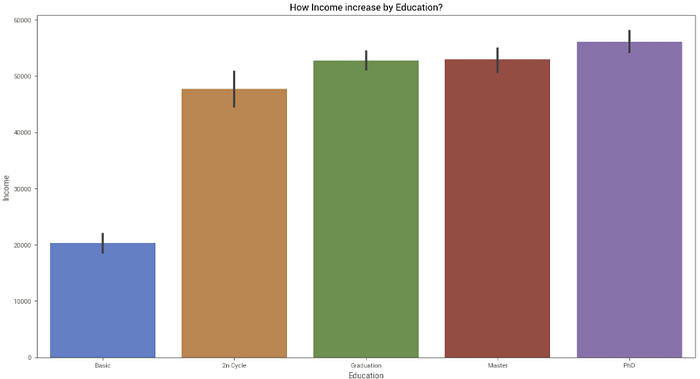
Além disso, a variável Income apresenta alguns outliers que podem impactar no processo de machine learning.
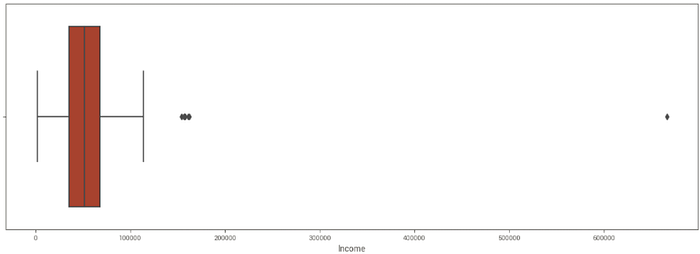
A remoção dos outliers se fez necessária, através da técnica IQR. Depois do processamento, o gráfico boxplot referente à Income ficou mais interessante para nosso propósito.
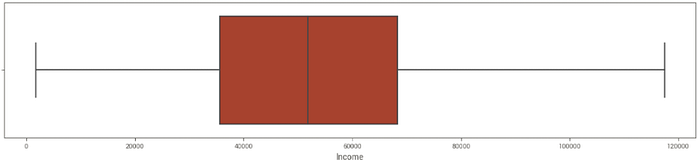
O histplot também passou a apresentar uma distribuição mais próxima à normal.
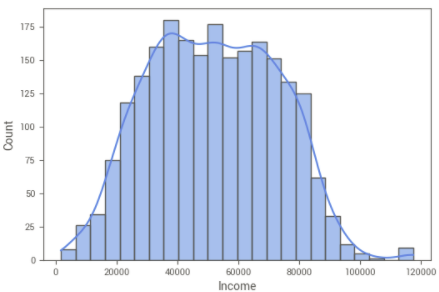
Criação de variável Total_Spent (total gasto) e Total_Purchases (total de compras) — A renda tem impacto no total de gastos e compras?
Para aproveitar melhor os dados que temos referente a quanto cada cliente gasta em cada categoria de produtos e quantas compras ele tem em cada setor da empresa, criamos 2 novas variáveis que representam a soma de todos os gastos (Total_Spent) e a soma de todas as compras (Total_Purchases). Com isso, podemos analisar a relação entre a renda e o quanto o cliente movimenta em valores financeiros para a empresa.

Percebemos que, como o esperado naturalmente, uma renda maior se reflete, no geral, em maior volume de compras e gastos.
Impacto da resposta às campanhas no total gasto por cliente
Como temos 2 variáveis que se referem à resposta de campanhas de marketing e ao tempo que o cliente está inativo, sem realizar uma compra, vamos analisar o impacto delas no total gasto.
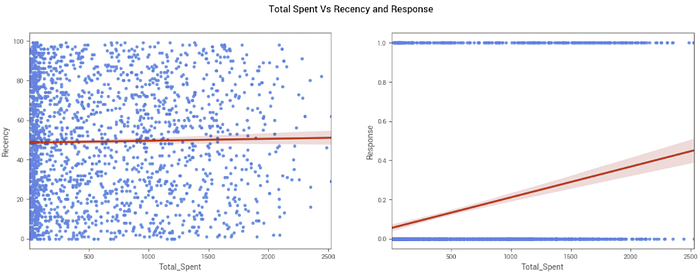
Vemos que o gráfico da direita mostra que o total gasto aumenta quando temos um cliente que responde às campanhas de marketing, sugerindo que as campanhas são efetivas. Já o gráfico da esquerda mostra que não há uma relação forte entre o tempo que o cliente está inativo e o total que ele gasta com a empresa.
Análise de efetividade das campanhas de marketing — Quais são as melhores campanhas que a empresa utiliza?
O conjunto de dados apresenta campos que determinam se o cliente aceitou alguma das 5 fases da campanha de marketing da empresa. Assim, podemos avaliar a soma de clientes que aceitaram cada uma.
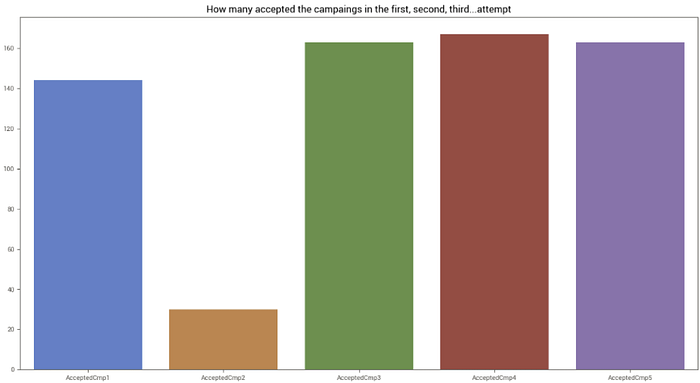
Vemos que a campanha número 2 (AcceptedCmp2) temum índice de aceite muito menor que o restante, o que sugere que essa campanha deve ser revista pelo time de marketing a fim de melhorar o seu desempenho.
Também avaliamos o impacto do aceite às campanhas no total gasto.
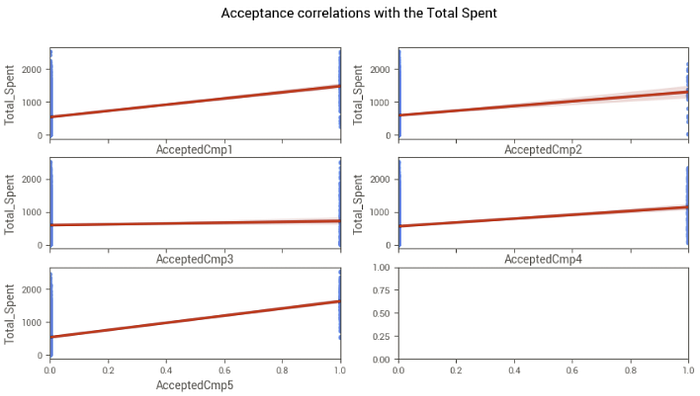
Os gráficos mostram que quando um cliente aceita cada uma das campanhas, tende a ter um total de gastos maior, corroborando o insight de que as campanhas possuem efetividade de um modo geral.
Criação da variável Idade (Age) — A idade tem impacto na renda?
Nossos dados tem um campo chamado Year_Birth, que representa o ano de nascimento de cada cliente, contendo registro mínimo de 1893 e máximo de 1996. Utilizamos o método Z-Score para determinar os outliers e obtivemos o ano de 1932 como sendo o mínimo para obter dados sem discrepâncias. Como apenas 3 registros eram abaixo desse valor, retiramos os 3 do banco de dados e obtivemos uma distribuição mais próxima da normal. Realizamos então a análise do ano de nascimento versus a renda, que é uma das principais características de nossos clientes.

O gráfico da esquerda mostra a distribuição dos anos de nascimento e, o da direta, a relação entre a idade e a renda. Este último mostra uma relação negativa leve, ou seja, clientes mais velhos (que nasceram antes já que estamos tratando do ano de nascimento e não da idade) tendem a ter uma renda maior do que clientes mais novos, de um modo geral.
Criamos então um novo campo com a idade do cliente para facilitar o entendimento, utilizando a equação:
Idade = ano atual – ano de nascimento
Aproveitando o tratamento da variável, criamos um agrupamento da idade com a técnica binning, para facilitar o entendimento e o processamento dos dados pelos algoritmos de aprendizado de máquina, dividindo os clientes em 4 grupos de idade igualmente, com etiquetas de 0 a 3.
A variável idade tem relação com o canal utilizado para compras?
Com a nova variável criada, podemos avaliar se os clientes mais jovens tendem a comprar mais pela internet, por exemplo, ou se os clientes mais velhos e experientes possuem preferência por ofertas.
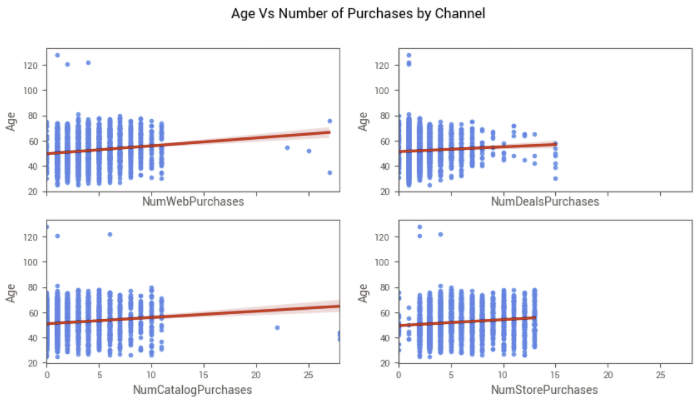
Os gráficos mostram que a idade tem uma leve relação com a quantidade de compras em cada canal, entretanto sempre positiva, significando que clientes mais velhos compram mais em todos os canais, refutando as primeiras suposições.
Já no caso das compras por categorias, podemos observar uma situação diferente:
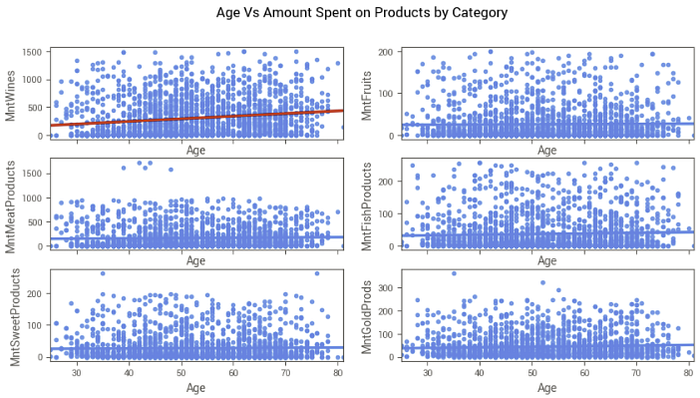
Vemos que, principalmente na categoria de vinhos (MntWines), clientes mais velhos tendem a gastar mais. Nas demais categorias, a linha de correlação é quase horizontal, indicando pouca ou nenhuma relação entre a idade e a quantidade gasta na categoria.
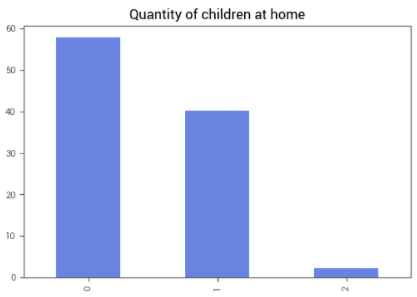
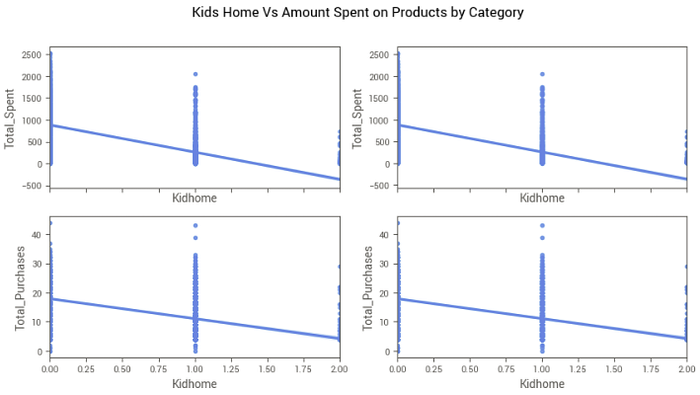
A variável Kidhome — A quantidade de crianças em casa influencia nas atividades de compras?
Nossos dados possuem clientes com 0, 1 ou 2 crianças em casa, sendo que a grande maioria não tem filhos.
Então, vamos analisar a relação das compras por canal com cada um dos filhos, para entender se pais preferem comprar quando existem ofertas, por exemplo.
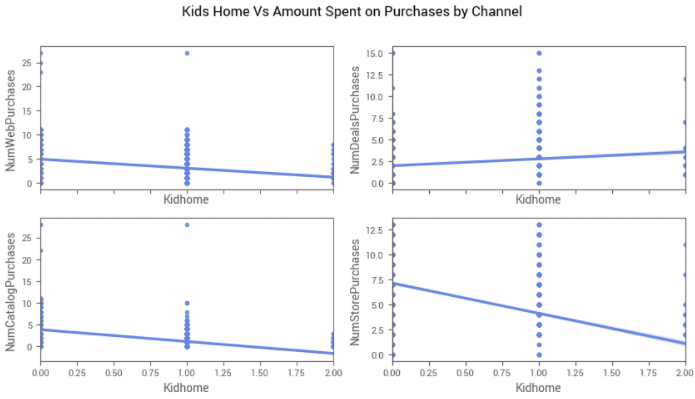
Percebemos que a relação é negativa quase sempre, ou seja, quem tem mais filhos, tende a comprar menos no geral em todos os canais, exceto em NumDealsPurchases, que determina as compras feitas por meio de promoções. Assim, vemos que quem tem mais filhos em casa, prefere sempre buscar por promoções e, em outras situações, compram menos.
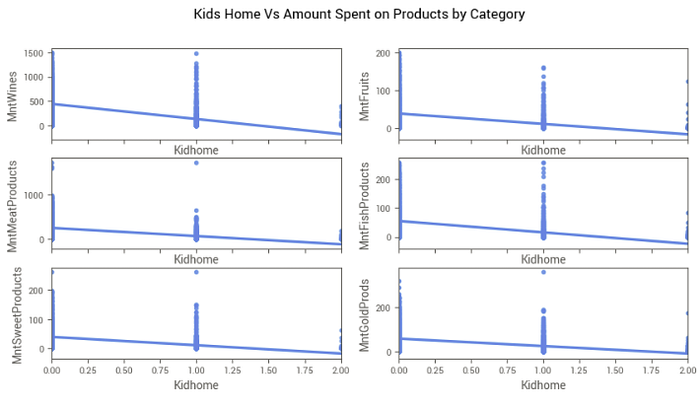
Os gráficos acima corroboram essa análise, mostrando que o total gasto por pessoas com mais crianças em casa é menor em todas as categorias de produtos. Abaixo vemos mais um gráfico considerando o total gasto e o total de compras levando em conta o número de crianças em casa.
Variável Estado Civil (Marital Status)
Encontramos estados civis estranhos, chamados “Absurd e YOLO”, que além de não serem estados civis em si, também eram discrepantes na análise de quantidade gasta em cada categoria e tinham pouquíssimos registros, permitindo a retirada deles do banco de dados sem muitos impactos negativos. Após retirar os registros, a análise de quantidade gasta em cada categoria é a seguinte:

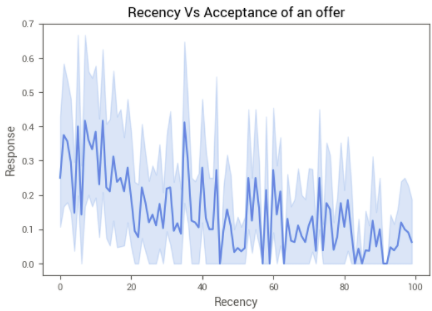
Variável Recency (tempo de inatividade) — Clientes que aceitam uma oferta têm menor tempo inativos?
A análise mostra que clientes que aceitam ofertas de campanha tendem a ter um menor tempo inativo junto à empresa, mais uma vez afirmando a efetividade de ofertas de promocionais na movimentação e interação dos clientes com a empresa.
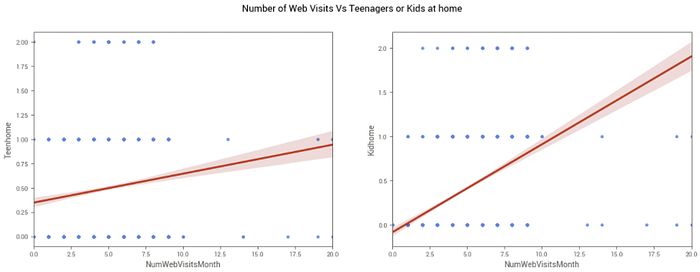
Número de visitas ao site (NumWebVisitsMonth) — Pessoas com mais crianças em casa acessam mais o site?
Percebemos que o número de acessos ao site é maior em pessoas com mais crianças em casa, mostrando tendência de busca por ofertas e maior tempo de pesquisa antes das compras.
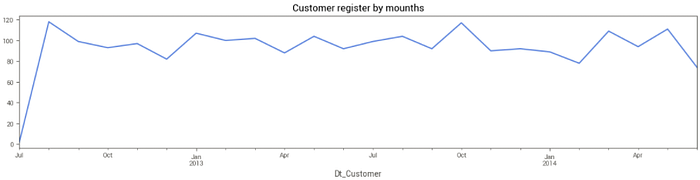
Análise temporal — Qual o mês em que se tem maior número de registros no site? Existe sazonalidade?
O número de registros de novos clientes no site não apresenta uma variação muito importante. No entanto, podemos apontar na série temporal que os meses de outubro de 2013, março e abril de 2014 tiveram boa performance, o que pode indicar boas campanhas de marketing no período. Isso desconsiderando o mês de agosto de 2012 que parece apresentar um alto valor de registros mas, por ser o início da série temporal, pode ser por uma questão técnica do banco de dados.
Já ao analisar o total de gastos geral e o total de compras geral, temos o seguinte gráfico, que mostra uma leve tendência de queda no total de gastos e estabilidade no total de vendas.
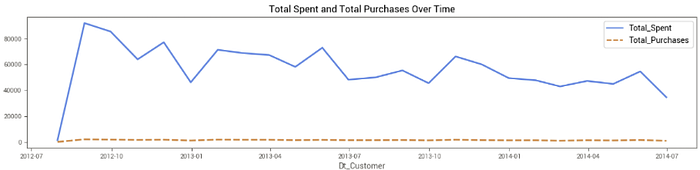
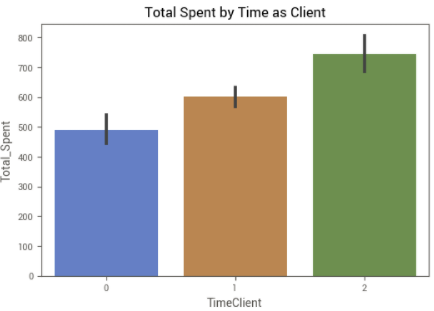
Tempo de relacionamento com a empresa — Qual a média de gastos de cada grupo?
O conjunto de dados mostra clientes de 2012 a 2014, fornecendo 3 anos de dados. Separamos então os clientes em 3 grupos, com 0, 1 ou 2 anos de relacionamento com a empresa e, depois, analisamos a média de gastos de cada um dos grupos.
Variável educação — Clientes mais graduados gastam mais em alguma categoria?
A categoria de vinhos é a que apresenta maior diferença entre o nível de escolaridade dos clientes em relação ao total gasto, sendo que os mais graduados gastam bem mais que os de educação básica. Na categoria de carnes, apenas os de educação básica são menos propensos a comprar e, nas demais, a diferença é menor entre esses grupos.
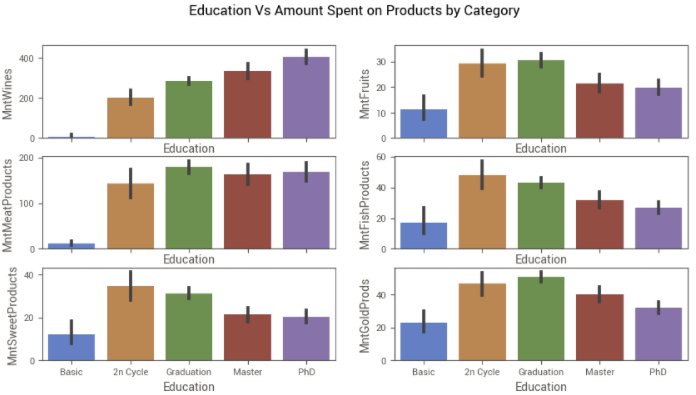
Já era de se esperar que os clientes de educação básica tivessem menores gastos no geral, já que também são os que possuem a menor renda na média. Mas é interessante perceber que na categoria de doces, o volume de gastos aumenta bastante de educação básica para fundamental, provavelmente por questão de renda, mas diminui conforme a graduação aumenta, já por questão de preferência. Também é interessante entender que a menor diferença entre os clientes de educação básica e os demais se dá na categoria de produtos de ouro.
Parte 2 | Modelos de Machine Learning para Segmentação dos Clientes
Encoding
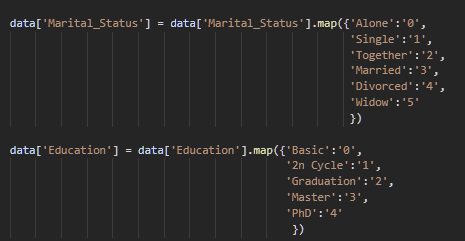
A primeira etapa é a transformação dos dados de modo que os algoritmos de machine learning tenham um melhor desempenho. Realizamos a codificação das colunas de Estado Civil e Educação utilizando o método map(), para controlar a ordem das etiquetas atribuídas.
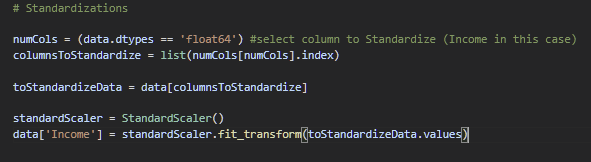
Padronização
Aplicamos a padronização nas colunas com tipo float64, afim de controlar o desvio padrão.
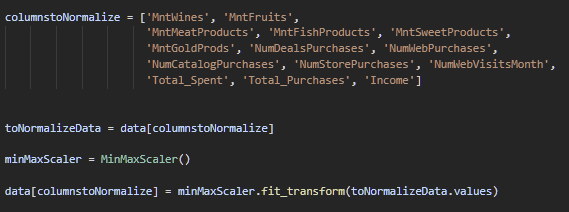
Normalização
Depois aplicamos a normalização nas colunas com variáveis contínuas, removendo então as discretas, obtendo assim valores normalizados de 0 a 1.
K-means para segmentação
Depois de testar vários modelos de classificação não supervisionada como DBSCAN, GaussianMixture, Birche e MeanShift, escolhemos o modelo K-Means para realizar o agrupamento dos clientes, já que ele obteve bons resultados. Utilizamos então os métodos de Elbow e Silhouette Coefficient juntamente com o método KneeLocator() da biblioteca Kneed, a fim de encontrar automaticamente o melhor número de clusters para cada uma das variáveis que escolhemos para segmentar, a saber ‘Income’, ‘Total_Purchases’ e ‘Total_Spent’. Também utilizamos a técnica desenvolvida por yasirroni para obtenção de clusters ordenados, de modo que os clientes com menor renda façam parte do cluster 0, e de maior renda, do cluster 1, e assim por diante.
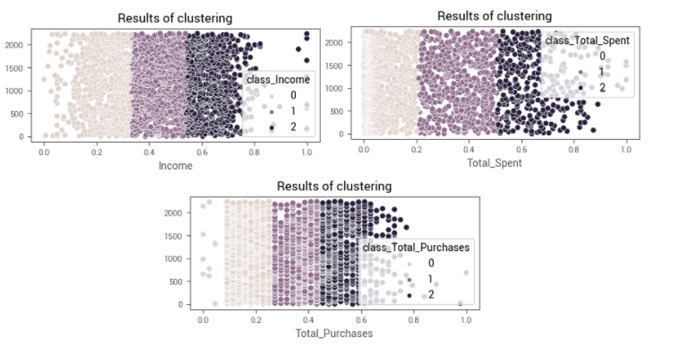
Obtivemos então 3 grupos de clientes (0–2) para cada uma das classes, criando um novo campo para cada um deles em nosso conjunto de dados onde 0 representa baixo score no grupo e 2 representa o maior score possível.
Segmentação Considerando os Agrupamentos
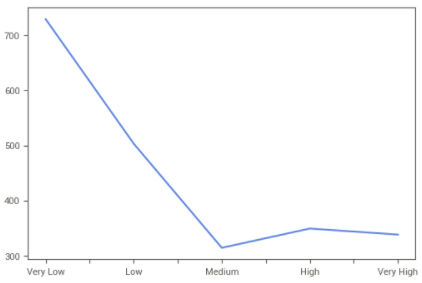
Potencial Renda x Gastos
Agora que ordenamos os clusters por receita, gasto total e compras totais, podemos calculá-los e segmentá-los usando combinações simples. Por exemplo, somar a classe Total Gasto com a classe Renda e obter pontuações para clientes com boa renda (2) e boas despesas (2), ou despesas muito altas(2) mesmo com renda não muito boa (1), mostrando certo potencial no contexto do negócio. Da mesma forma, podemos determinar clientes com orçamentos baixos (0) e despesas baixas (0), para que possamos investir menos esforço de negócios com eles. Consideraremos 5 grupos, que são: Potencial Muito Baixo, Baixo, Médio, Alto e Muito Alto, com o seguinte resultado de segmentação:
‘Potencial_Income_X_Expenses’ = ‘class_Income’ + ‘class_Total_Spent’
Potencial Considerando o Tempo Como Cliente
Aqui, consideramos as despesas potenciais versus a receita subtraindo o score do tempo de relacionamento com a empresa. O objetivo é dar uma pontuação mais alta aos clientes que têm uma boa pontuação de renda ou que gastam muito com menos tempo de relacionamento. Como resultado, os clientes que demoram mais para gastar, mesmo que um total razoável, recebem uma pontuação mais baixa.
‘Potencial_Over_Time’ = ‘class_Income’ + ‘class_Total_Spent’ – ‘TimeClient’
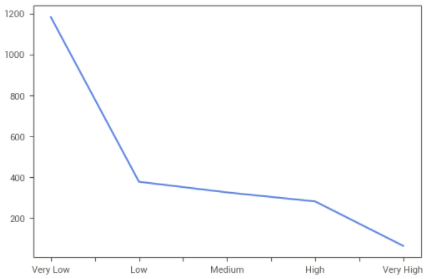
Segmento de Clientes que gasta muito além da média
Vamos considerar também clientes que gastam muito mais que a média, tendo como referência o quantil de 0,75, levando em consideração também o tempo de relacionamento com a empresa. Assim, os separamos em 2 grupos: os que estão acima da média e os que não estão.
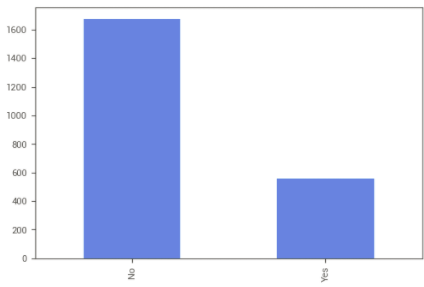
Tornando os resultados fáceis de entender para o time de marketing
Para que os dados possam ser utilizados pelos tomadores de decisões, exportamos um novo conjunto contendo apenas o ID do cliente e as segmentações que realizamos de um modo fácil de ler.
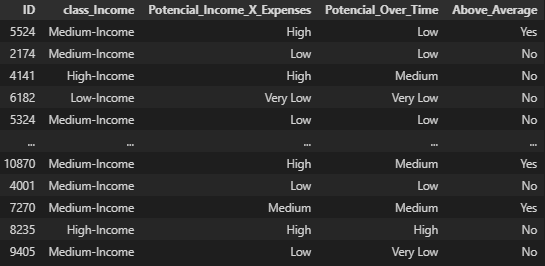
Parte 3 | Modelos de Machine Learning para prever o potencial de novos clientes
Podemos prever em qual categoria de potencial de gastos um cliente se encaixaria considerando os recursos que podemos coletar no primeiro contato?
Para responder a essa pergunta, utilizamos o algoritmo XGBoost para tentar prever a classe de gastos totais que um novo cliente se encaixaria logo ao se cadastrar na empresa. Nesse momento, provavelmente teríamos acesso apenas às variáveis ‘Education’, ‘Marital_Status’, ‘Kidhome’, ‘Teenhome’, ‘Age_score’, ‘class_Income’, sendo as duas últimas decorrentes de processo de feature engineering prévio.
Conclusão da previsão com Machine Learning
Usando o modelo XGBoost, conseguimos prever com 77% de respostas corretas a classe de despesas em que o novo cliente se encaixaria. Não é um índice muito alto, mas já é possível usar essa previsão para estratégias de marketing no estágio inicial de relacionamento entre empresa e cliente, oferecendo suporte à tomada de decisões de marketing e campanhas para, depois, com o decorrer do tempo, coletarmos mais dados e aplicarmos os agrupamentos anteriores.
Conclusão
Com o conjunto de dados fornecido tivemos a oportunidade de analisar profundamente o comportamento de cada grupo de cliente com a empresa. Também conseguimos segmentar os clientes em 3 categorias diferentes, cada uma considerando distintas variáveis que podem ser utilizadas de modos diferentes pelo time de marketing e apoiar a tomada de decisões. Também desenvolvemos um sistema de machine learning que pôde prever com 77% de acerto a categoria de gastos na qual um novo cliente estaria e, assim, apoiar o time de marketing na tomada de decisões assim que o cliente se cadastra e preenche os dados iniciais, de modo que com o tempo, o comportamento desse consumidor seria analisado e ele poderia ser atribuído aos agrupamentos detalhados com dados observados.
Referências
https://www.kaggle.com/imakash3011/customer-personality-analysis
https://www.analyticsvidhya.com/blog/2021/05/feature-engineering-how-to-detect-and-remove-outliers-with-python-code/
https://machinelearningmastery.com/standardscaler-and-minmaxscaler-transforms-in-python/
https://machinelearningmastery.com/clustering-algorithms-with-python
https://realpython.com/k-means-clustering-python/#partitional-clustering
https://github.com/yasirroni/sorted_cluster