
A Tarefa
Para este projeto tenho disponível um extenso banco de dados de uma grande rede de lojas de varejo russa, que oferece detalhes sobre vendas de cada produto, por cada loja em uma granularidade diária.
A partir desse conjunto de dados detalhado, tenho o desafio de prever, para o próximo mês, quantas unidades de cada produto serão vendidas em cada uma das lojas.
O grande desafio desse projeto é considerar lojas que não operam mais, produtos que sofreram vendas exageradas em determinadas épocas e outros fatores que exigem a construção de um modelo de Machine Learning robusto o suficiente para generalizar as previsões.
Parte 1 – Business Intelligence & Data Cleaning
Primeiros Passos
Primeiro, realizei as tarefas de EDA e limpeza dos dados, a fim de executar a transformação do sistema OLTP recebido para um esquema OLAP, para viabilizar as análises.
Insights
Quantidade de produtos vendidos por dia
O dado mais importante neste projeto é referente à quantidade de produtos vendidos por dia. Após as análises percebi que a imensa maioria de vendas de cada produto é de 1 por dia, no máximo. No entanto, existe grande interferência de outliers, percebidos claramente na análise de quartis, que são sempre 1.
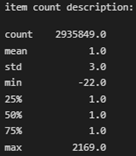

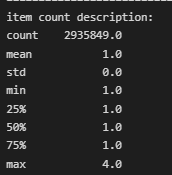
Também encontrei valores negativos, que sugerem compras devolvidas, canceladas ou até mesmo problemas no estoque. Realizei então a remoção dos outliers utilizando a técnica IQR, chegando ao seguinte resultado:
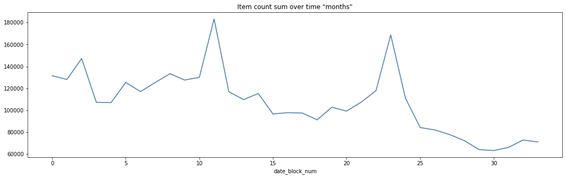
Verificação de Sazonalidade e Tendências
Também analisei quais estados obtêm o maior número de vendedores, com vistas ao número de vendas. Com isso, é Ainda sobre a variável de quantidade diária de vendas, analisei as tendências e a sazonalidade, encontrando padrões definidos.
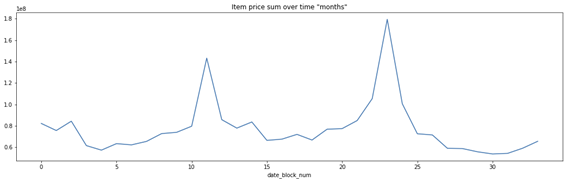
A variável Item_price, que é definida como o faturamento do dia, como esperado, segue semelhantes características temporais de sazonalidade.
Utilizando a técnica de decomposição da série temporal, cheguei ao seguinte resultado.
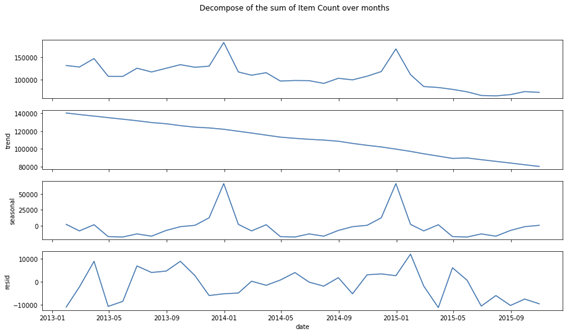
Depois, retirei os elementos de tendência para deixar mais clara a sazonalidade, já observada nas análises acima. Com esse processo, a sazonalidade fica ainda mais evidente.
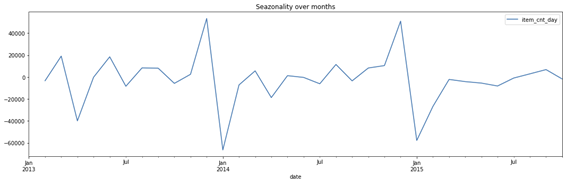
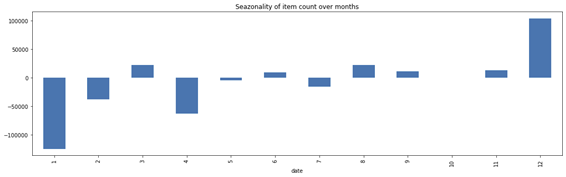
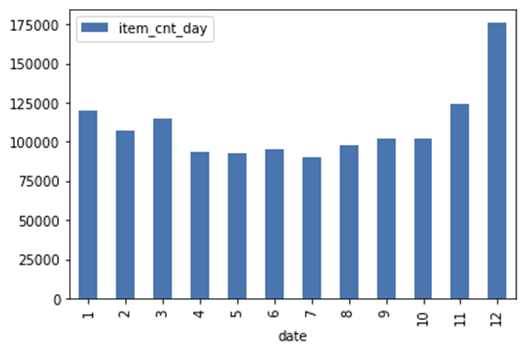
Ou seja, temos um elemento sazonal importante com alta na venda de produtos nos meses de dezembro e estabilidade nos meses do meio do ano.
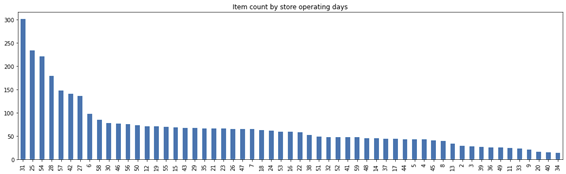
Classificação das melhores lojas
O conjunto de dados oferece detalhes sobre cada loja em uma granularidade diária. No entanto, muitas lojas pararam de operar há vários meses, o que limitaria seus resultados no geral acumulativo.
Resolvi então classificar as lojas com melhor desempenho proporcionalmente aos dias em que elas estiveram em operação, oferecendo suporte às decisões do time de marketing. Para isso, criei variáveis que indicam a quantidade de dias em que cada loja operou. Logo, as melhores lojas são as de ID 31, 25, 54, 28 e 57.
Criação de categoria de produtos por similaridade em seus nomes
Os dados trazem os nomes de cada item vendido. Como encontrei 22.170 diferentes produtos, resolvi criar uma segmentação de categorias através da similaridade de seus nomes. Assim, produtos com nomes semelhantes foram agrupados em 12 categorias diferentes, oferecendo mais uma variável para o modelo de Machine Learning.
Para esse propósito, utilizei técnicas Fuzzing e de Text Clustering, por meio da biblioteca Text Pack que proporcionou o melhor desempenho no processamento dos dados.
Parte 2 — Data Science
Desconsideração das lojas inoperantes
Como o objetivo final é prever as vendas para o próximo mês, vou desconsiderar as lojas que estão inoperantes há mais de 30 dias, já que obviamente elas não terão vendas no próximo mês e, então, não existe o que prever já que será 0.

Feature Engeneering, Auto-Correlation e agrupamento mensal
Utilizei técnicas de Feature Engeneering para criação de variáveis de suporte ao sistema de inteligência artificial. Depois de determinar a auto correlação parcial entre os valores mensais, criei variáveis que definem quantos produtos iguais foram vendidos nos meses anteriores em cada loja, aproveitando as medidas sazonais para ajudar o modelo preditivo.
Também realizei o agrupamento dos dados por mês agregando os valores, já que a meta é prever valores do mês seguinte e temos os dados em granularidade diária.
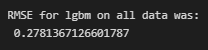
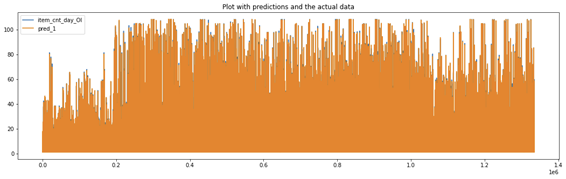
Predição utilizando LGBM
Depois de vários testes utilizando as técnicas de Pipeline, resolvi implementar o modelo LGBM, que obteve os melhores resultados gerais. O conjunto de testes obteve excelente resultado de RMSE:
Conclusão
Depois de gerar insights valiosos de BI, fui capaz de prever a quantidade de vendas para o próximo mês e retirar insights importantes para o time de marketing:
– Defini quais foram as lojas de maior performance, considerando o tempo em operação.
– Agrupei os produtos em categorias que consideram as semelhanças em seus nomes.
– Defini os elementos de sazonalidade e de tendência de vendas para apoiar o time de marketing.
– Realizei a previsão para as vendas futuras em cada loja, de cada produto individualmente.
– O conjunto de validação retornou um RMSE de 1.23517.
Apesar do resultado aceitável, ainda tenho espaço para melhoria do modelo, visando diminuir o overfitting, principalmente. Novas melhorias serão implementadas com objetivo de estudo assim que possível.
Referências
https://github.com/lukewhyte/textpack
https://www.kaggle.com/code/deinforcement/top-1-predict-future-sales-features-lightgbm/
https://github.com/seatgeek/thefuzz