
A Tarefa
A tarefa é realizar a predição de mortes e da gravidade que a doença COVID-19 poderia atingir em determinado paciente, considerando as variáveis medidas e estruturadas no dataset fornecido por Harsh Walia através de um repositório no kaggle.com. Os dados foram disponibilizados já com os processos de pré-processamento necessários, apresentando coesão, variáveis bem definidas e, em alguns casos, agrupadas.
O propósito é determinar os estados com os melhores índices de concluir a tarefa, primeiro precisamos utilizar um modelo de aprendizado de máquina para prever qual será a gravidade da doença no paciente. Assim, quando ele entrar no hospital poderá realizar as medições e obter uma previsão de gravidade do seu caso. Depois, com a previsão de gravidade realizada, podemos utilizar um segundo modelo para prever se o paciente sobreviverá ou não, utilizando AUC Score como métrica de validação.
EDA — Exploratory Data Analyses
Primeiros passos
O primeiro passo é a realização da análise exploratória dos dados, para garantir o entendimento do que temos disponível.
Descobrimos que o conjunto de dados não possui dados nulos e tem o total de 4711 registros e 85 variáveis. Algumas features tratam de grupos de outras features semelhantes (“Troponin > 0.1”, por exemplo, é uma feature binária derivada da original “Troponin”). Outros exemplos incluem as features com “score” no nome, que se tratam de agrupamentos.
Também levamos em consideração que as variáveis LOS (tempo que o paciente ficou internado) e Death (se ele morreu ou sobreviveu) não serão conhecidas na entrada de um novo paciente. Por esse motivo não utilizaremos essas features para evitar Data Lekeage.
Análise mais profunda das features
Analisando mais profundamente as features de “Age”, percebemos que a maioria dos pacientes no conjunto de dados tinha entre 0–60 anos, com 1854 entradas nesse grupo. No entanto, a média de idades é de 63 anos e a mediana de 65 anos, o que sugere que pacientes mais velhos tendem a precisar mais do hospital nos casos de COVID-19.
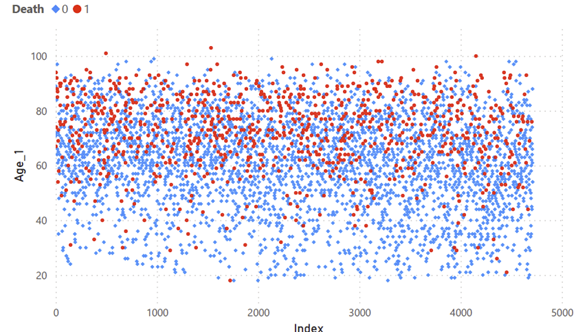
Também foi possível perceber uma tendência de maior probabilidade de morte relacionada à idade do paciente, em que pacientes mais velhos têm menores chances de sobreviver, como é mostrado no gráfico a seguir, produzido no Microsoft Power BI.

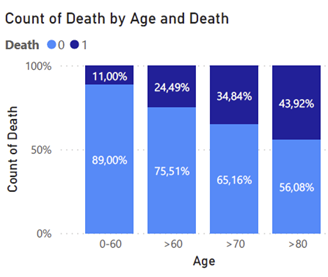
A feature “Severity”
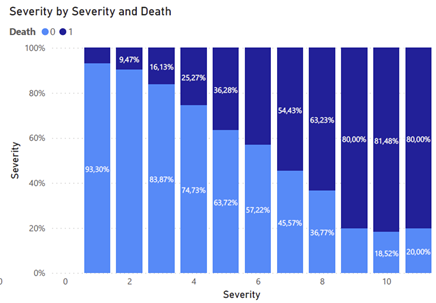
A feature “Severity” também tem um papel importante no entendimento dos dados. Essa variável está dividida em 12 classes, de 0–11, onde 0 representa uma baixa gravidade e 11 uma gravidade severa. A partir da análise, entendemos que quanto maior gravidade, maior a proporção de pacientes que não sobrevive.
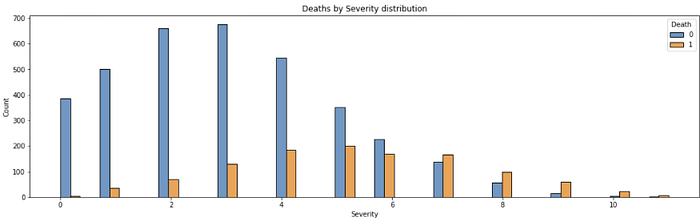
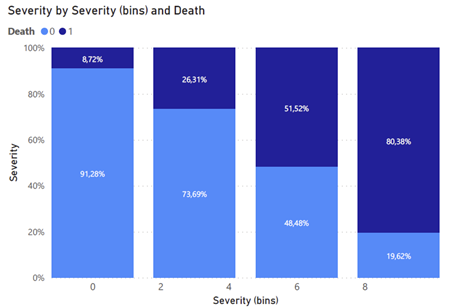
Podemos separar essa feature em grupos menores, também. A partir da visualização abaixo, percebemos que os 3 últimos grupos de “Severity” têm uma taxa muito semelhante de mortes (~80%). As três classes anteriores também possuem uma taxa semelhante entre elas, o que nos permite agrupar essa feature para reduzir a dimensionalidade e, assim, facilitar a previsão em nosso modelo. O segundo gráfico representa essa feature já reagrupada em 4 novas classes de 0–3, chamada “Severity_class”, onde 3 representa casos mais graves e 0 os mais leves.
Padronização e feature engineering
Padronização
Após a análise inicial partimos para a preparação do conjunto de dados. Como temos várias features que possuem escalas diferentes de observação, aplicamos a padronização em todas as features que representam escalas próprias, excluindo assim as binárias e as categóricas. Com isso, mantemos um desvio padrão de 1 para todas essas variáveis.

Data transformation
Como temos sinais como ”<” e “>” nos nomes das colunas, é uma boa prática alterar esses sinais para um texto mais simples, uma vez que alguns algoritmos como o XGClassifier possuem restrições quanto ao uso desses caracteres. Realizamos então essa transformação.

Criação de nova feature
Como visto anteriormente na etapa de EDA, podemos agrupar os valores de “Severity” e criar uma nova feature utilizando o método .cut(), da biblioteca Pandas. Assim, temos uma nova categoria criada a partir do conceito de “Binning”. Vale ressaltar que essa nova feature é criada com um DType “Categorical”, o que pode ser um problema na hora de ajustar o modelo de aprendizado de máquina. Transformamos ela para “int64” para evitar esse problema.

Correlações
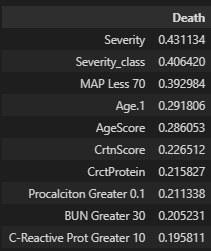
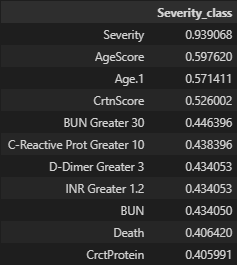
Partimos agora para a determinação da correlação entre as variáveis, a fim de encontrar as variáveis mais interessantes para o nosso modelo e descartar as que não possuem muita relevância nesse contexto. Calculamos o índice de correlação com a classe “Death” e com a classe “Severity”, já que vamos prever as duas classes num segundo momento.
Escolha das features
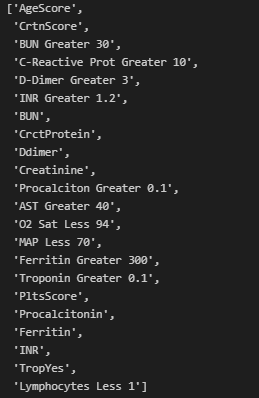
Após realizar a verificação das correlações, podemos escolher as variáveis mais propensas a ajudar nosso modelo em suas predições. Utilizando as 25 features mais bem pontuadas na correlação com “Severity_class”, obtemos:

Modelos de Aprendizado de Máquina
Previsão de “Severity_class”
Com as features principais já escolhidas, partimos para a escolha do melhor algoritmo de aprendizado de máquina para nosso caso. No entanto, antes de qualquer coisa precisamos dividir nosso conjunto de dados em partes para treino e de validação do modelo, utilizando o método train_test_split do scikit-learn.
Criamos então um pipeline básico com 5 modelos iniciais: randomForestClassifier, SVC, GaussianNB, LogisticRegression e XGBClassifier. O objetivo é obter uma classificação geral utilizando a técnica de Cross_Validation, para poder escolher o modelo mais interessante e investir no ajuste dos seus hyperparâmetros. Os resultados obtidos mostraram como modelos mais promissores: XGClassifier, Logistic Regression e SVC.
Depois de realizar testes com alguns hyperparâmetros, escolhemos o XGClassifier que, em seu ajuste final forneceu acurácia de 96% para as previsões de “Severity_class”.

Previsão de “Death”
Uma vez que temos um modelo ajustado para prever a gravidade da doença, podemos efetuar a previsão de sobrevivência ou morte do paciente. Para isso, escolhemos as 24 variáveis com maior correlação com a classe “Death”, verificadas anteriormente.
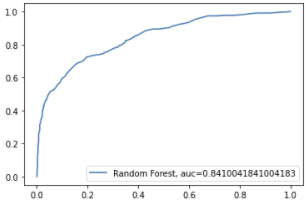
Após a divisão da base de dados novamente em treino e validação, criamos um novo pipeline com modelos e a técnica cross_val_score, a fim de encontrar o modelo mais promissor, que neste caso foi o randomForestClassifier, obtendo ACC de 82%.
Partimos então para a modelagem final, com ajustes nos hyperparâmetros e com a validação considerando a métrica AUC Score, que era exigência inicial da tarefa. O resultado da AUC no modelo final ficou em 0.84.
Conclusão
Com a chegada de um novo paciente com COVID-19 no hospital, podemos realizar todos os exames que correspondem às variáveis encontradas no nosso conjunto de dados e utilizar essas informações para prever, inicialmente, a gravidade da doença, separada em 4 classes diferentes, entre 0 e 3. Depois, utilizamos um método de concatenação para unir os dados aferidos do paciente em sua entrada e a gravidade prevista para, então, prever se o paciente está em um grupo de risco de morte.
Referências
https://machinelearningmastery.com/standardscaler-and-minmaxscaler-transforms-in-python/
https://www.kaggle.com/imperiopts/predict-severity-and-deaths-of-covid-19-patients