
A Tarefa
A partir de um conjunto de dados gerado em um sistema OLTP de um grande marketplace brasileiro, tenho a missão de transformar os conjuntos para um ambiente OLAP e o analisar a fundo, gerando insights para o suporte à tomada de decisões.
O propósito é determinar os estados com os melhores índices de receita, categorias de produtos com as melhores avaliações, os motivos pelos quais os clientes avaliam positiva ou negativamente as compras, analisar o tempo de entrega (atrasos vs antecipações) e, em um segundo momento, aplicar técnicas de segmentação de clientes e de previsão de receita para os próximos meses.
Parte 1 — Business Intelligence
Primeiros Passos
Depois de realizar a tarefa de Análise exploratória dos dados e transformar as features necessárias, parti para transformações entre o ambiente OLTP e OLAP, necessária para nossas análises. Percebi a importância de realizar joins e merges com cuidado nesse caso para evitar dados duplicados, já que as chaves primárias e estrangeiras poderiam ser agrupadas e com isso criarem registros duplicados de valor de compra, por exemplo.
Insights
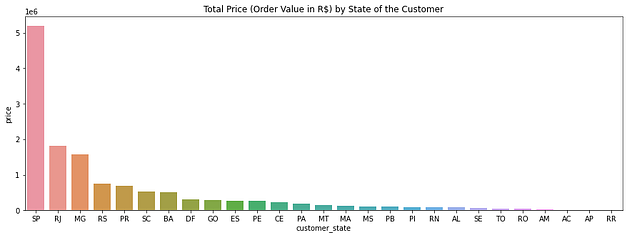
Estados com maiores receitas
Determinei com uma análise dos dados, os estados que possuem maior receita de compras em R$, assim podemos traçar objetivos de marketing eficientes.
Estados com maior número de vendedores
Também analisei quais estados obtêm o maior número de vendedores, com vistas ao número de vendas. Com isso, é possível pensar em soluções estratégicas visando o vendedor.

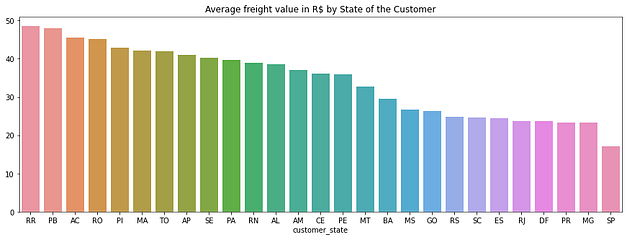
Valor médio do frete para cada estado
Calculei o valor médio do frete para cada estado para definir os que possuem maior custo e verificar se é interessante criar pontos de distribuição ou buscar parcerias que diminuam esse valor, dependendo das receitas geradas por cada um e das regras do negócio.
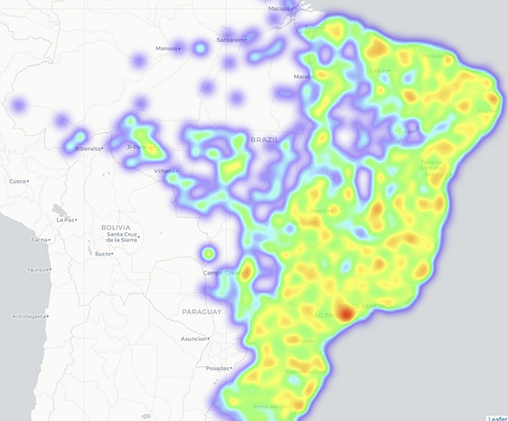
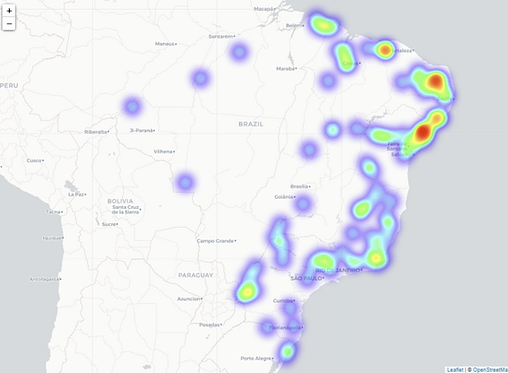
Mapa com posição geográfica de clientes ativos
Criei então um mapa interativo, com o posicionamento geográfico e cada um dos clientes ativos encontrados no conjunto de dados, proporcionando uma visão detalhada e esclarecedora sobre onde se tem mais e menos consumidores que realizam compras.
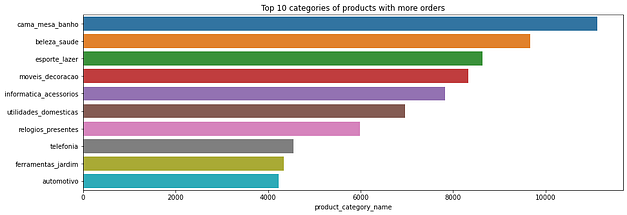
Produtos com maior número de compras
É importante descobrir quais são as categorias de produtos com maior número de vendas, que geram maior receita e movimentação no site.
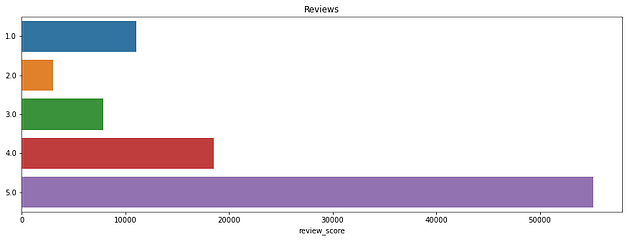
Reviews
Analisando o conjunto de dados que possui os valores das avaliações, notei que a grande maioria possui 5 estrelas, mas como existem bastantes avaliações negativas com 1 estrela, vou analisar também as motivações.
Média de avaliações por estado do vendedor e do comprador
Verifiquei se o estado do vendedor ou do comprador possui alguma relação com as classes de avaliações, para entender se os fatores culturais ou de regiões específicas têm influenciado a empresa em questão. No entanto, apenas os vendedores do Acre e Amazonas apresentam uma discrepância importante nas médias de avaliações recebidas, algo que pode ser analisado pela equipe da empresa.

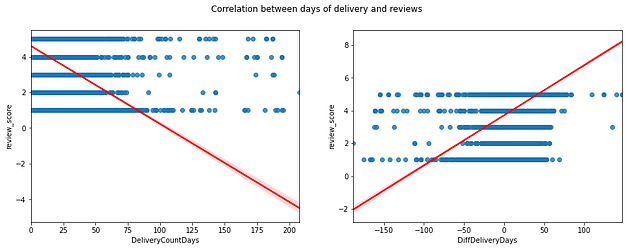
Variáveis de entrega e relação com avaliações
Para investigar a relação entre o tempo de entrega com as avaliações, calculei novas variáveis de tempo de entrega (em dias) e atrasos/antecipações (em dias). Depois, examinei a correlação com as avaliações, percebendo uma forte correlação.
Calculei também os números absolutos de médias de avaliações para entregas atrasadas e antecipadas, o que mostrou que este é um dos fatores mais importantes para avaliações positivas ou negativas.
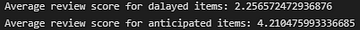
Processamento de linguagem natural para avaliações
Processei a linguagem natural utilizada pelos consumidores nas avaliações para gerar, graficamente, insights sobre quais termos são mais utilizados em avaliações positivas e negativas, chegando aos seguintes resultados:

Definição dos piores vendedores
Através das análises anteriores, percebi que o fator entrega é um dos mais importantes. Logo, com a criação da variável de atrasos/antecipações (em dias), que chamei de DiffDeliveryDays, pude definir quais são os piores vendedores nesse quesito, considerando a soma dos dias de atraso para cada um, mostrando apenas os 5 piores abaixo mas com a possibilidade de definir os 100 piores, por exemplo. Com isso, a equipe de marketing pode providenciar ações para resolver o problema.

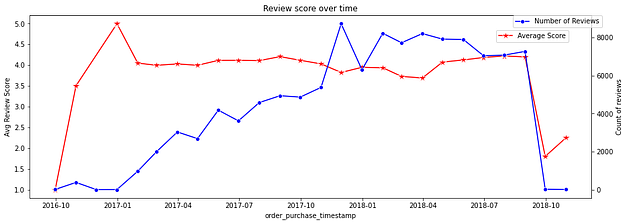
Melhora ou piora nas avaliações com o tempo
Analisando a série temporal, pude investigar se as avaliações melhoraram ou pioraram de um modo geral, chegando à conclusão de que elas se mantiveram parecidas. Para analisar mais concisamente, tracei um paralelo entre o número total de avaliações e a média dos valores avaliados, por isso desconsiderei o pico de valores (jan/2017) e o pior nível (out/2018), que possuem pouquíssimas avaliações, provavelmente por problemas técnicos do site, invalidando as médias.
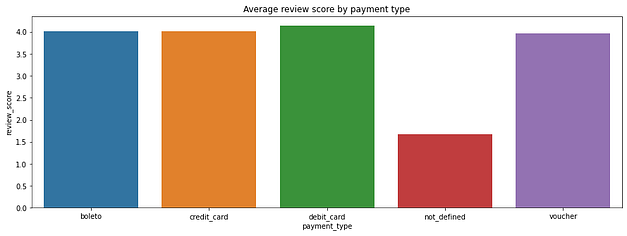
Avaliações de acordo com o tipo de pagamento
Suspeitei que, como o conjunto de dados apresenta muitos pagamentos por vouchers promocionais, talvez este seria um fator importante em relação às avaliações. No entanto, essa suspeita foi refutada observando as médias de avaliação por método de pagamento. Apenas os pagamentos “not_defined” possuem menor média, provavelmente por compras malsucedidas.
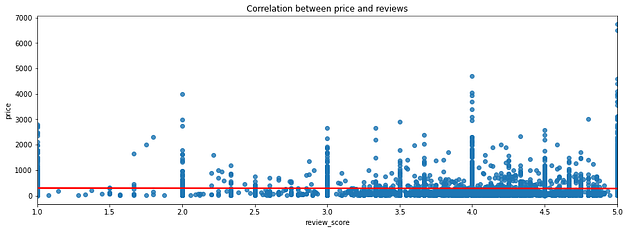
Relação entre preço da compra e avaliação
Investiguei a correlação entre o preço das compras e as avaliações para verificar se produtos mais caros ou mais baratos tendem a receber melhores qualificações pelos clientes. Porém, não existe essa tendência.

Categorias de produtos e suas avaliações
Para concluir essa análise, desconsiderei as categorias que possuíam poucas vendas, já que resultariam em médias de avaliações irrelevantes para a análise geral.

Média de atrasos visto no mapa
Como percebi que o principal fator pertinente à melhoria das avaliações é mesmo o tempo de entrega (em especial os atrasos), calculei as regiões que apresentam os piores índices de atraso na média e representei graficamente. Assim o time de logística poderia traçar um plano para diminuir o tempo de entrega para determinados locais, especialmente na região nordeste, nesse caso.
Parte 2 — Data Science
Aplicação de técnica de RFM para segmentação de clientes
Criação de variáveis relevantes
Para aplicar a técnica RFM, criei 3 novos campos no conjunto de dados, considerando quando foi a última compra, a quantidade total de compras e o valor total gasto por cliente, a fim de segmentar cada consumidor em um grupo específico para apoiar as campanhas de marketing.
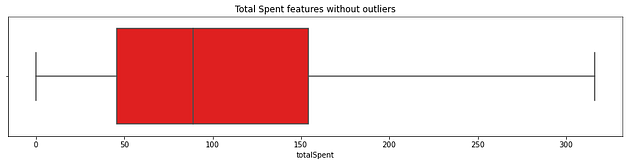
Com isso, percebi a necessidade de tratar os outliers no quesito de total gasto, para melhorar o sistema de agrupamento, partindo dos dados originais a seguir:

Para um conjunto mais normalizado, chegando ao resultado abaixo:
Agrupamento de clientes utilizando K-Means
Implementei então o algoritmo K-Means através de uma função desenvolvida para agrupar os clientes de acordo com cada uma das variáveis desejadas, neste caso “dias desde a última compra”, “total gasto” e “total de compras”. Assim, cada cliente recebe um score para cada uma dessas variáveis através de uma função replicável que garante um sistema mais intuitivo.
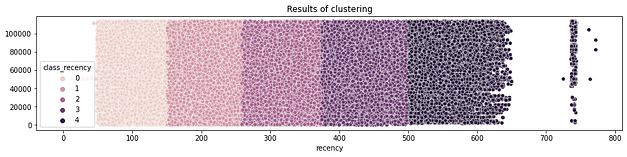

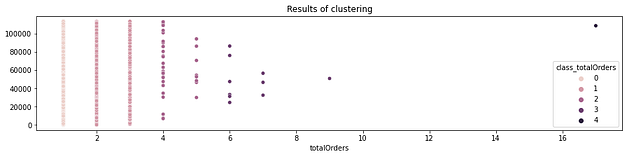
RFM — Segmentação de acordo com o status do cliente
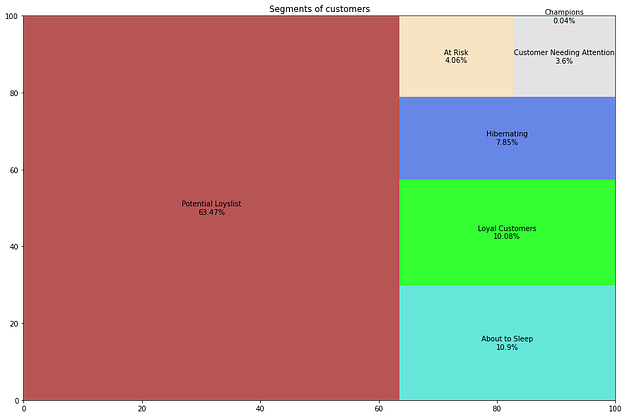
Realizei então cálculos específicos para a utilização dessa técnica, que resultaram na segmentação dos clientes em grupos com valor semântico para o time de marketing. Cada cliente possui, agora, uma atribuição de grupo junto ao seu ID no conjunto de dados.
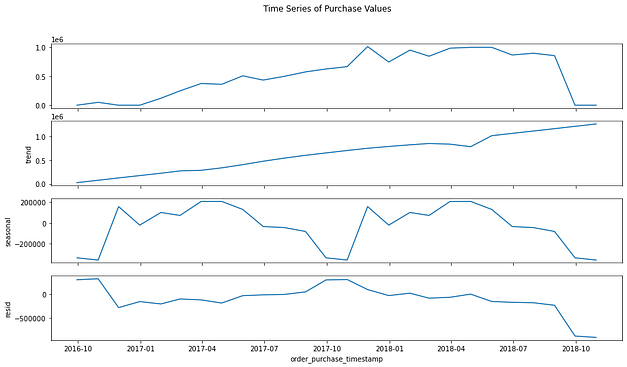
Análise da série temporal
Com isso, apurei detalhadamente a série temporal de receitas, realizando a decomposição dos dados para verificar a existência de fator sazonal, a tendência geral ao longo do tempo e o resíduo – ou erro.
Predição das receitas para os próximos meses
A partir daí, com a definição do fator sazonal mais clara graficamente e a linha de tendência apresentando uma alta constante, realizei a predição das receitas para os próximos meses utilizando modelo de regressão e também com o algoritmo Auto-ARIMA, considerando que o conjunto de dados apresentava registros apenas até 2018.
O modelo de regressão utilizado foi o XGBoost Regressor, que apresentou uma excelente adaptação aos dados como mostra o gráfico a seguir que considera o conjunto de treino e teste, sendo que a linha vermelha representa as predições para um conjunto de dados não utilizado no treinamento do modelo:
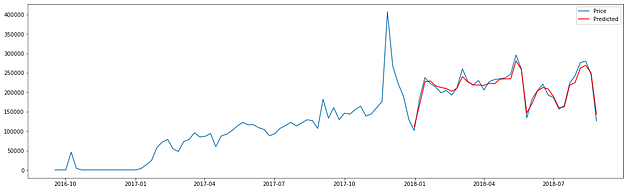
Com isso, pude prever o faturamento para a semana imediatamente seguinte à última do conjunto de dados, obtendo o resultado:
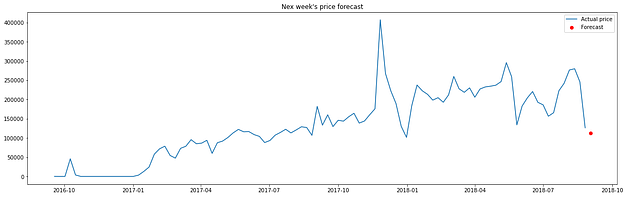
Já o modelo auto-Arima facilita a previsão de médio prazo, gerando o gráfico de predições que é representado pela linha verde. Seguindo a ordem natural, essas previsões poderiam facilitar o desenvolvimento de metas pelo time responsável.

Conclusão
Analisando cada uma das variáveis, pude obter insights importantes sobre os clientes do site Olist:
– Separei os piores vendedores em termos de entrega, para que se possa criar uma estratégia a fim de contornar a situação.
– Estabeleci precisamente os locais com maiores atrasos e, por isso, é possível definir objetivos logísticos para resolver o problema.
– Demonstrei quais termos são usados nas avaliações positivas e negativas.
– Pude fazer uma previsão de receita para as próximas semanas, apoiando a equipe que vai traçar as metas.
– Demonstrei as tendências sazonais que afetam a receita.
– Segmentei os clientes usando técnicas de RFM, agrupando cada um em um subgrupo que pode ser usado pela equipe de marketing para direcionar campanhas específicas.
– Defini geograficamente onde estão os clientes ativos.
– Analisei quais categorias de produtos obtêm os melhores desempenhos nas avaliações e quantidade de vendas.
– Indiquei quais estados têm os fretes mais caros, quais têm mais vendas, quais têm as maiores compras e o faturamento de cada um.
Referências
https://towardsdatascience.com/time-series-forecasting-using-auto-arima-in-python-bb83e49210cdPeterson F